Studio della camminata
tramite accelerometri e sistemi GPS
Università degli studi di Firenze
_________________
_____
FACOLTÀ DI SCIENZE MATEMATICHE FISICHE E NATURALI
Corso di laurea in Informatica
Studio della camminata
tramite accelerometri e sistemi GPS
Candidato:
Samuele Carli
______________________________________________________________________________
Anno Accademico
2007/2008
This work is licensed under the Creative Commons Attribution 3.0 United States License. To view a copy of this license, visit http://creativecommons.org/licenses/by/3.0/us/ or send a letter to Creative Commons, 171 Second Street, Suite 300, San Francisco, California, 94105, USA.
“Chi non ha mai commesso un errore
non ha mai provato a fare qualcosa di nuovo.”
Albert Einstein
Il posizionamento autonomo di precisione, inteso come misura delle velocità tenute e degli
spazi percorsi senza interazione con il mondo esterno, è un argomento che suscita interesse
da lungo tempo: dal tracciamento delle traiettorie dei missili balistici alla navigazione
automatica inerziale degli aerei di linea commerciali, dal movimento di bracci meccanici ad
applicazioni biomediche o sportive, negli ultimi cinquant’anni le idee messe in gioco sono
state innumerevoli.
La tecnologia odierna permette di costruire sensori accelerometrici di buona precisione e di
dimensioni sufficientemente ridotte da poter essere utilizzati in una serie molto vasta di
contesti, ma il problema numerico di ricostruire dei dati utili e precisi dalle misure
accelerometriche è ancora aperto: esistono soluzioni semplici ed efficaci oppure i
problemi intrinseci legati all’integrazione di segnali rumorosi non sono risolvibili?
Esistono soluzioni universali oppure ogni problema deve essere affrontato in maniera
diversa?
Questo lavoro è nato con lo scopo di valutare i risultati che si possono ottenere
da un particolare sistema accelerometrico progettato e realizzato da un’azienda
italiana.
Nel primo capitolo si prende in considerazione il problema generico di ricostruire un
movimento a partire dall’accelerazione misurata dallo strumento in dotazione. Già dalle
prime misure sperimentali vengono alla luce i seri problemi dovuti alle derive stocastiche
degli integrali e conseguentemente vengono presentati alcuni tentativi di porvi rimedio
attraverso semplici metodi numerici; in letteratura molte fonti propongono i filtri di Kalman
come ottima soluzione al problema e pertanto ne è stata considerata l’applicabilità in
questo contesto.
L’osservazione dei risultati ottenuti ha suggerito l’inesistenza di metodi che siano al tempo
stesso semplici, decontestualizzati e in grado di fornire risposte utili; il filtro di Kalman è
uno strumento potente ma si è rivelato utile soltanto quando si hanno a disposizione più
fonti di informazione da incrociare.
Si è quindi proseguito su questa strada considerando un caso particolare: la misurazione del
passo in una camminata.
A questo scopo viene presentato un metodo che, rilevando i singoli passi, è in grado di
fornire risposte credibili. Per migliorare i risultati del metodo si è deciso di prendere in
considerazione l’utilizzo di una fonte di informazioni esterne come il Global Positioning
System; a tal fine ne sono state considerate le caratteristiche e quindi l’applicabilità nel
contesto dello studio della camminata, a partire dai molti lavori che si trovano in
letteratura.
Il problema della ricostruzione del movimento di un corpo nello spazio conoscendo la sua accelerazione istantanea ha un primo approccio molto semplice ed intuitivo. Indicando con a(t) la funzione che rappresenta l’andamento dell’accelerazione del corpo nel tempo lungo un asse, con una integrazione si ottiene subito:
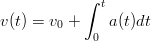 | (1.1) |
che è ancora una funzione del tempo e rappresenta la velocità istantanea del corpo. Mediante un’altra integrazione si arriva subito alla funzione:
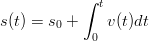 | (1.2) |
che è la soluzione al problema iniziale, ovvero si ha una funzione del tempo che rappresenta
la posizione nello spazio del corpo considerato.
Nella pratica non si ha a disposizione l’andamento dell’accelerazione in forma funzionale, ma solo un’approssimazione per campioni equidistanti nel tempo. Indicando con τ l’inverso della frequenza di campionamento, ovvero la durata di un periodo, e con a[t] la misura corrispondente al quanto che spazza l’intervallo di tempo [tτ, (t + 1)τ], le integrazioni (1.1) e (1.2) possono espresse in questo modo:
![t−1
∑
v[t] = v0 + τ a[t], t = 1, 2,...,n
0](tesi3x.png) | (1.3) |
e
![t∑−1
s[t] = s0 + τ v[t], t = 1, 2,...,n
0](tesi4x.png) | (1.4) |
I valori a[t] sono il risultato di un processo di digitalizzazione e sono soggetti ad errori
di misura che vengono introdotti sia durante il processo di quantizzazione (che per
definizione impone l’approssimazione di una grandezza continua con una discreta), sia
durante il processo stesso di misura (dovuti presumibilmente al tipo di sensore, alle
tolleranze di realizzazione, etc. ).
Il processo di integrazione di un segnale affetto da errore (o rumore) è soggetto a una
deriva di ordine di grandezza proporzionale al numero di passi di integrazione (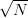 per la
prima integrazione, ≈ N
per la
prima integrazione, ≈ N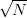 per la seconda, [6, 7]). Questo rende di fatto impraticabile
l’applicazione diretta delle formule (1.3) e (1.4), dato che l’integrazione anche su soli 250
campioni può comportare un errore significativo; occorre trovare un metodo per eliminare o
quantomeno limitare la ripercussione degli errori di misura sul risultato del calcolo.
per la seconda, [6, 7]). Questo rende di fatto impraticabile
l’applicazione diretta delle formule (1.3) e (1.4), dato che l’integrazione anche su soli 250
campioni può comportare un errore significativo; occorre trovare un metodo per eliminare o
quantomeno limitare la ripercussione degli errori di misura sul risultato del calcolo.
L’accelerometro fornisce valori numerici di 8 bit, ovvero ad ogni misura corrisponde un
numero intero x ∈ [0, 255]. Secondo le specifiche tecniche l’accelerometro ha un fondoscala
di 6g, ovvero si dovrebbe ottenere come output 0 misurando −6g e 255 misurando +6g
con una risoluzione di 12∕256 = 0.046875g∕digit.
In realtà ogni accelerometro, per motivi tecnologici di tolleranze di realizzazione, si
comporta in maniera leggermente diversa e talvolta non esattamente simmetrica: la
risoluzione risulta leggermente peggiore (circa 0.055g∕digit) e diversa per ogni
asse.
Le caratteristiche reali dell’accelerometro usato per le misure effettuate durante questo
lavoro, ricavate sperimentalmente, sono riportate in appendice B.
In questa sezione sono illustrati alcuni dei metodi sperimentati finalizzati alla ricostruzione di movimenti unidimensionali generici. Lo scopo di questi metodi è quello di valutare se sia possibile mitigare il fenomeno delle derive agendo direttamente sul segnale accelerometrico senza conoscere il tipo di moto che si vuole misurare.
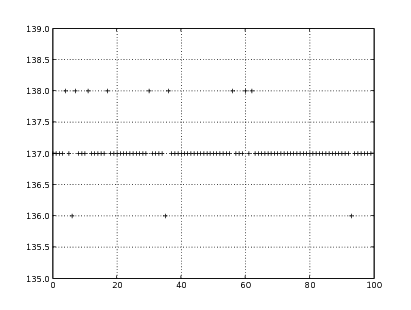
Il primo problema che ci si trova ad affrontare è relativo al comportamento dell’accelerometro
fermo. Come si vede in figura 1.1, la misura che si ottiene è costituita da una serie di valori
che oscillano intorno al quanto che più si avvicina al valore reale. Le oscillazioni non
hanno una distribuzione uniforme intorno al quanto in questione, ma questa si
sposta verso il quanto precedente o successivo in funzione del valore reale della
misura.
Queste oscillazioni sono però la causa principale della divergenza dei processi di
integrazione, i quali darebbero origine a risultati migliori in presenza di un segnale meno
preciso ma non affetto da rumore.
La prima cosa che si fa è “lisciare” i valori ottenuti ed eliminare per quanto possibile le fluttuazioni intorno allo zero. Indicando con A[x] l’array che contiene i valori misurati, si modifica ogni campione secondo la regola:
![w
scaleF actor x+∑ 2-
A[x] = ------------ F tol(A[i],aT ol,off set)
w i=x− w-
2](tesi8x.png) | (1.5) |
dove w rappresenta il numero di campioni che si vogliono mediare, aTol la tolleranza per le fluttuazioni sull’accelerazione, offset il valore corrispondente allo zero, scaleFactor il fattore di scala da quanti a m∕s2 e la funzione Ftol(x,y,z) è così definita:
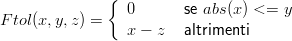 | (1.6) |
Così facendo si ottiene come risultato uno smoothing come mostrato in figura 1.2; questo
non risolve completamente il problema dell’integrazione, ma permette di usare il valore
precedentemente ricavato come zero in maniera efficace.
Si calcola quindi la velocità come integrazione cumulativa dei valori in A:
![∑x
V[x] = dt A [i]
i=0](tesi10x.png) | (1.7) |
Se la tolleranza aTol sull’accelerazione è stata scelta bene, la funzione di smoothing è
sufficiente a far si che l’integrale non diverga quando l’accelerometro è fermo, in quanto
riesce a smorzare efficacemente tutte le oscillazioni stocastiche senza sacrificare troppo la
precisione di misura.
Il problema del rumore rimane tuttavia durante la fase di moto dell’accelerometro, e questo
rende difficile una misura accurata della velocità finale del corpo. Quello che succede infatti
è che la deriva dell’integrale dovuta al rumore, insieme ad una non perfetta simmetria
rispetto allo zero dell’accelerometro, impedisce al valore finale dell’integrale di tornare
esattamente a zero anche solo dopo un moto molto breve e deciso del sensore;
questo fatto ha un risultato disastroso in quanto si considera che il corpo viaggi a
velocità costante quando questo invece è fermo, il che introduce un errore che si
ripercuoterà su tutte le misure future che saranno eseguite da questo momento in
poi.
É quindi necessario introdurre una tolleranza anche sul valore finale della velocità, che
permetta di arginare il problema, almeno parzialmente, imponendo la velocità finale (o la
variazione di essa) nulla , anche se l’integrale non ha come risultato esatto zero,
ovvero:
 | (1.8) |
Per il calcolo dello spostamento infine si procederà per integrazione della velocità
secondo l’equazione (1.4). Si può vedere un risultato ottenibile con questo metodo nella
figura 1.3.
Con questo metodo si ha una stabilità accettabile quando il sensore è fermo e si riesce a
ottenere una precisione nell’ordine del centimetro su metro su dei movimenti semplici e
decisi. Il risultato è però molto influenzato dal tipo di movimento a cui viene soggetto
l’accelerometro; se questo risulta poco deciso o comunque troppo prolungato nel tempo
l’accumulazione degli errori porta molto spesso fuori dalle tolleranze sulla velocità e rende
inservibile la misura.
In conclusione questo metodo risulta applicabile in contesti particolari dove i
movimenti sono decisi e ben limitati nel tempo, ma non per movimenti generici del
sensore.
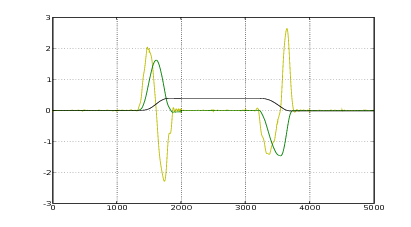
Un approccio diverso consiste nell’approssimare l’andamento dell’accelerazione per mezzo di un polinomio interpolante. Si cerca un polinomio della forma:
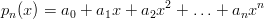 | (1.9) |
che sia interpolante i dati misurati. La scelta del grado del polinomio è delicata e va
operata in funzione sia della grandezza dei blocchi di campioni che si vogliono considerare,
sia del tipo di movimento che si sta misurando (variazioni di accelerazione per secondo).
Sperimentalmente, sulla dimensione dei blocchi di 500 campioni e per il tipo di movimento
testato, il grado 8 si è rivelato un buon compromesso. Il risultato dell’applicazione di questo
metodo è visibile in figura 1.4.
L’approssimazione per mezzo di polinomi ha il vantaggio di permettere il calcolo della
prima integrazione con un costo computazionale molto ridotto e un’elevata precisione. Si
può ricavare matematicamente il polinomio che approssima la velocità:
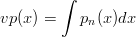 | (1.10) |
e quindi ottenere l’andamento della velocità valutando vp(x) sui vari istanti di campionamento:
![∫ t
V [t] = vp(t) + A[0] = pn(t)dt
0](tesi19x.png) | (1.11) |
Anche in questo caso si rende necessaria l’adozione di una tolleranza sul valore finale
della velocità, secondo l’equazione (1.8). Come nel caso precedente si va poi a calcolare lo
spazio secondo l’equazione (1.4), per ottenere un risultato come quello in figura
1.5.
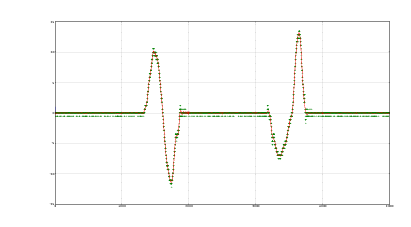
In conclusione questo metodo non offre vantaggi rispetto al metodo delle tolleranze: la
stabilità della misura spaziale a sensore fermo è peggiore (le oscillazioni sono più
pronunciate), il costo computazionale è molto più elevato e il risultato non è
sostanzialmente diverso dal primo, come si può vedere in figura 1.6.
Guardando con occhio critico i risultati ottenuti con i metodi appena presentati, si
conclude immediatamente che trovare una soluzione valida e semplice al caso del moto
generico con elaborazione in real time non è un problema che ammette una soluzione
semplice ed allo stesso tempo efficace. Gli errori stocastici di misura non sono modellabili e
generalmente non hanno una distribuzione fissa ma dipendente dal contesto fisico
momentaneo in cui si trova il sensore; questo rende di fatto molto difficile, se non
impossibile, apportare delle correzioni al segnale dell’accelerazione che siano compatibili con
la realtà, e in generale queste correzioni difficilmente possono risolvere il problema delle
derive degli integrali.
Se si conosce, anche solo parzialmente, il tipo di movimento che si vuole studiare, la
costruzione di un modello per il moto solitamente porta numerosi vantaggi. In generale, un
modello ha lo scopo di fornire delle informazioni sulle reazioni che il corpo deve avere in dei
contesti noti, cosa che permette di apportare delle correzioni sensate sia al risultato
delle integrazioni del segnale, sia direttamente al segnale misurato, se si rivela
necessario.
Una ipotesi che non pone pesanti restrizioni sul tipo di movimento è la seguente:
Nella pratica infatti il moto uniforme è raro, e un corpo in movimento è soggetto
quantomeno a vibrazioni di entità rilevabile. Sotto questa ipotesi possono essere
considerate molte tipologie interessanti di movimento, ad esempio quelli di un braccio
robotico, di un carrello, di un mouse e così via.
L’ipotesi (1.1) si concretizza suddividendo il calcolo della velocità su una serie di intervalli, ciascuno dei quali comprende un intervallo di tempo in cui il sensore è sicuramente fermo oppure si sta sicuramente muovendo:
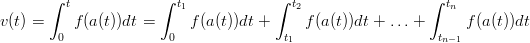 | (1.12) |
dove:
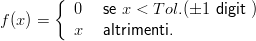 | (1.13) |
Per la determinazione degli intervalli di integrazione si usa un semplice algoritmo:
Se il corpo si sta muovendo si cerca la condizione 2a) oppure (2c), altrimenti se il corpo è fermo si vuole trovare l’inizio del nuovo moto (se ne è iniziato un’altro), ovvero la condizione (2b) oppure (2c).
In questa forma, per chiarezza di esposizione, l’algoritmo ha come precondizione che il sensore
sia fermo e non accelerato all’istante zero; non è problematico modificare il punto
1 affinché riconosca la situazione iniziale di quiete o di moto e si comporti di
conseguenza.
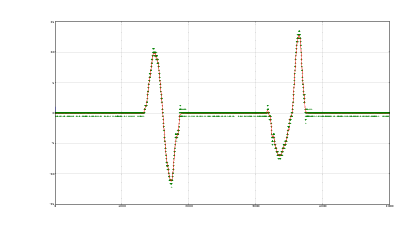
Un risultato dell’applicazione di questo metodo è mostrato in figura 1.7, insieme a un
confronto diretto con il metodo delle tolleranze in figura 1.8. Questo metodo non è in
grado di risolvere il problema dell’accumulazione degli errori sulla seconda integrazione, ma
l’ipotesi sul tipo di moto permette di riconoscere quando il corpo si ferma con una semplice
analisi diretta del segnale dell’accelerazione e quindi di azzerare la deriva del primo
integrale ogni volta che il movimento lo permette.
Ne consegue che limitatamente ai tipi di moto conformi all’ipotesi (1.1), questo metodo
fornisce risultati migliori rispetto ai due metodi presentati precedentemente. In particolare
con i primi due metodi accade facilmente che, anche considerando un movimento molto
semplice come quello in figura 1.3, il valore calcolato della velocità alla fine del moto
ecceda la tolleranza e quindi si inizi a considerare il corpo in moto a velocità costante anche
se in realtà è fermo; questo implica che da quel momento in poi la posizione calcolata
sarà completamente sbagliata, sia come valore che come andamento. Con questo
metodo invece quanto appena descritto non può accadere; la posizione calcolata è
sicuramente inaccurata quanto quelle calcolate con i metodi precedenti a causa delle
derive stocastiche, ma ha il pregio di rispecchiare sicuramente l’andamento del
moto.
Nelle situazioni in cui il moto ha caratteristiche precise e conosciute, i risultati che si
riescono ad ottenere sono buoni.
Ad esempio, se si considera un moto rettilineo di andata e ritorno (simile a quello usato
negli esempi precedenti), si hanno elementi sufficienti per apportare correzioni alle derive
degli integrali. In particolare si sa che ci sono due movimenti, ed al termine del
secondo il sensore è tornato alla posizione iniziale. L’integrazione diretta sui dati non
fornisce risultati utili (figura 1.9, ma l’imposizione sulla seconda integrazione degli
zeri migliora la situazione in modo molto evidente (figura 1.10). Nell’esempio la
correzione è imposta sommando all’integrale risultante una funzione pari e una dispari
pesate in modo opportuno; questo metodo è spiegato nei dettagli nel capitolo
2.
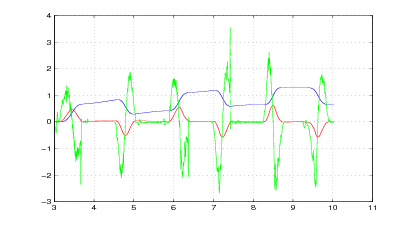
Il problema della determinazione del movimento a partire da informazioni parziali e
incomplete o da misure indirette è ben noto e ammette molte soluzioni.
Uno degli approcci al problema più in voga in letteratura fa uso di un particolare tipo di
filtro originariamente concepito da Rudolph E. Kalman [8]. Per capire l’idea che sta alla
base del filtro, si considera un caso particolarmente semplice che permette di comprendere
vantaggi e limiti che possono venire da informazioni legate alle equazioni del moto di un
sistema.
Si consideri una nave alla deriva di cui si vuole stimare la posizione; la nave si sta
muovendo in modo non esattamente rettilineo uniforme a causa delle onde del mare, e la
posizione della nave può essere calcolata soltanto mediante misure astronomiche. Il
problema è come si possano integrare le informazioni di posizione che si ottengono dal
sestante con la conoscenza che la nave si muove, entro certe deviazioni stocastiche,
secondo un moto conosciuto. Si assuma che la nave si stia muovendo secondo la
legge:
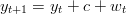 | (1.14) |
dove c è lo spazio che la nave percorre in un secondo, considerando la velocità media della
nave costante, e wt il rumore relativo dovuto alle onde del mare agitato (per esempio
c = 5m mentre il rumore è bianco con varianza σw).
La misura diretta della posizione all’istante t viene chiamata xt ed è affetta da un rumore
bianco vt:
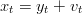 | (1.15) |
dove vt ha varianza σv. Se non ci sono altre informazioni ci si aspetta quindi che la posizione all’istante t + 1 sia data da:
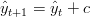 | (1.16) |
La grandezza ŷt ha varianza σt indipendente da c per cui la varianza complessiva è la somma pitagorica delle due varianze:
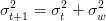 | (1.17) |
Se non vengono effettuate ulteriori misure, l’incertezza sulla posizione continua ad
aumentare e la deriva della nave porta ad errori crescenti. Se invece si ha a disposizione
un’ulteriore misura astronomica al tempo t + 1 le due misure si possono combinare in modo
indipendente.
La misura di ŷt+1 ha quindi due risposte:
Il risultato è quindi:
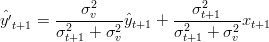 | (1.18) |
che ha una varianza:
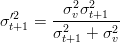 | (1.19) |
la quale è comunque più piccola della minore delle due varianze.
La presenza di un errore infinito su una delle due misure rende inutile la procedura (e
questo è il caso in cui una delle due misure non viene effettuata); il crescere della
confidenza nei confronti di una delle due misure (σ → 0) tende invece a escludere l’altra
dal calcolo.
Queste equazioni possono anche essere espresse in una forma più compatta e adatta al
calcolo. Si definisce:
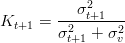 | (1.20) |
Successivamente, dalla (1.17) e dalla (1.19) si deriva:
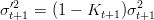 | (1.21) |
e infine:
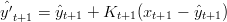 | (1.22) |
Nel listato 1.1 si riporta una semplice implementazione di quanto appena esposto, utilizzata per generare le figure 1.11, 1.12 e 1.13 che mostrano la posizione della nave prevista dal filtro al variare della confidenza nei confronti della misura astronomica o della vicinanza del movimento della nave al moto rettilineo uniforme.
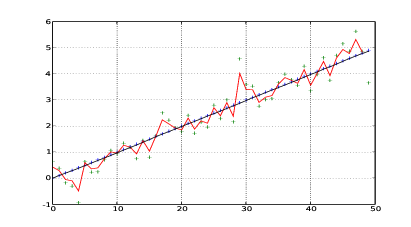
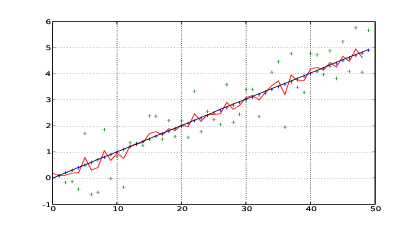
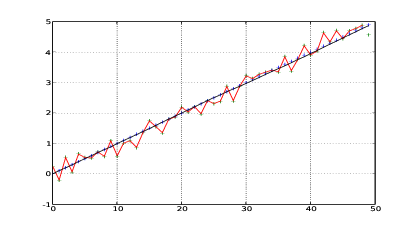
Un filtro di Kalman è costituito da un insieme di equazioni che implementano un
estimatore di tipo predictor-corrector; la stima che si ottiene è ottimale nel senso che
minimizza la covarianza dell’errore, quando certe condizioni al contorno sono verificate.
Questa formalizzazione, proposta in [1], è una generalizzazione del filtro per sistemi il cui
stato è rappresentato da un numero arbitrario di caratteristiche.
L’idea alla base è quella di generare una approssimazione dello stato di un processo.
Il processo è rappresentato dal vettore di stato x ∈ ℝn, avviene su una base
dei tempi discreta ed è governato da un’equazione differenziale stocastica del
tipo:
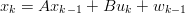 | (1.23) |
Lo stato xk è correlato ai dati misurati z ∈ ℝm:
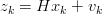 | (1.24) |
dove la matrice H ∈ Mm×n rappresenta la relazione tra lo stato reale del processo e la misura zk. Le variabili stocastiche wk e vk rappresentano il rumore rispettivamente sul processo e sulla misura. Si assuma che questi rumori siano indipendenti, bianchi e con una distribuzione gaussiana:
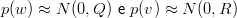 | (1.25) |
Si definisce con  k− ∈ ℝn la stima a priori al passo k ottenuta in base alla conoscenza
che si ha del comportamento del processo nei passi avvenuti prima di k, e con
k− ∈ ℝn la stima a priori al passo k ottenuta in base alla conoscenza
che si ha del comportamento del processo nei passi avvenuti prima di k, e con 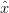 k ∈ ℝn la
stima a posteriori data la misura zk; le stime a priori e a posteriori dell’errore possono esser
espresse come:
k ∈ ℝn la
stima a posteriori data la misura zk; le stime a priori e a posteriori dell’errore possono esser
espresse come:
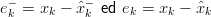 | (1.26) |
Questi errori hanno una covarianza:
![− − −T − T
Pk = E [ek ek ] e Pk = E [ek ek]](tesi44x.png) | (1.27) |
Rimane da trovare un’equazione per calcolare la stima a posteriori  k come combinazione
lineare della stima a priori
k come combinazione
lineare della stima a priori 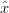 k− e una differenza pesata tra la misura attuale z
k e la
predizione sulla misura H
k− e una differenza pesata tra la misura attuale z
k e la
predizione sulla misura H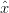 k−. Questa equazione è del tipo:
k−. Questa equazione è del tipo:
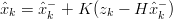 | (1.28) |
La matrice K ∈ Mn×m è scelta1 tale da minimizzare la covarianza a posteriori (seconda equazione in (1.27)):
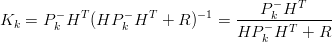 | (1.29) |
Da questa forma di K si nota che al diminuire della covarianza sulla misura R (eq. (1.25)),
l’importanza del termine (zk −H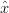 k−) (generalmente chiamato residuo) in (1.28) aumenta;
nello specifico:
k−) (generalmente chiamato residuo) in (1.28) aumenta;
nello specifico:
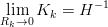 | (1.30) |
Nello stesso tempo al diminuire della covarianza dell’errore stimato a priori Pk− il residuo perde di importanza, ovvero:
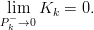 | (1.31) |
Si ha quindi che al diminuire della covarianza sulla misura questa tende ad acquistare
fiducia (ovvero il risultato del filtro si avvicina di più a zk) facendo perdere fiducia nei
confronti della misura predetta H k−; al contrario al diminuire della varianza
dell’errore stimato a priori il filtro tende a privilegiare i valori predetti rispetto a quelli
misurati.
k−; al contrario al diminuire della varianza
dell’errore stimato a priori il filtro tende a privilegiare i valori predetti rispetto a quelli
misurati.
Applicazione al caso discreto
Il filtro di Kalman approssima un processo agendo come un sistema reazionato: esso
computa una predizione sullo stato del processo in un certo istante di tempo e
ottiene un feedback sotto forma di misure rumorose. L’insieme di equazioni che
compongono il filtro può quindi essere diviso in due sottoinsiemi: uno contiene le
equazioni che eseguono una predizione sullo stato futuro del processo e della
covarianza dell’errore, l’altro contiene le equazioni che si occupano di inglobare il
risultato della misura nelle stime a priori al fine di ottenere delle predizioni future più
accurate.
La predizione viene effettuata secondo le equazioni:
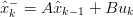 | (1.32) |
per quanto riguarda la misura all’istante k, e:
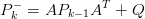 | (1.33) |
per stimare la covarianza dell’errore. A seguito della misura zk si calcolano gli aggiornamenti:
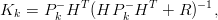 | (1.34) |
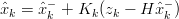 | (1.35) |
e infine
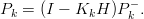 | (1.36) |
Il processo di filtraggio avviene quindi in due fasi:
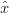 k−1,Pk−1 attraverso le equazioni (1.32) e (1.33) (fase di aggiornamento
temporale o time update);
k−1,Pk−1 attraverso le equazioni (1.32) e (1.33) (fase di aggiornamento
temporale o time update);
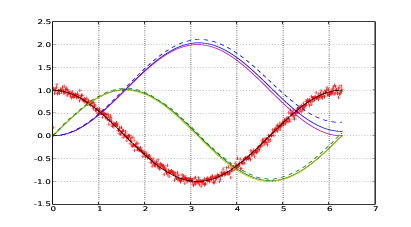
Comportamento del filtro di Kalman semplice nel caso della doppia integrazione Si prenda in considerazione un corpo che subisce un’accelerazione su un asse secondo la legge:
![a(t) = cos(t) con t ∈ [0,2π ]](tesi60x.png) | (1.37) |
La velocità del corpo si ottiene in maniera esatta:
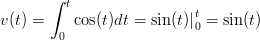 | (1.38) |
come anche lo spazio:
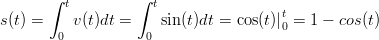 | (1.39) |
Si può simulare una misura reale campionando la funzione a(t) a intervalli regolari; per
questo scopo si definisce il periodo di campionameno dt al valore arbitrario dt = 0.01,
ovvero si considera la funzione campionata in ⌊2π∕dt⌋ = 628 punti.
Si definisce la funzione apert(t) la funzione a(t) soggetta a perturbazioni:
![apert(t) = a(t) + random , t ∈ [0,0.01,⌊2π ∕dt⌋]](tesi63x.png) | (1.40) |
dove il numero casuale è stato scelto secondo una distribuzione gaussiana (per far fede
all’ipotesi di base dei filtri di Kalman).
Per avere un’idea sull’andamento delle derive, si definiscono le integrazioni semplici
come:
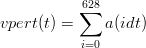 | (1.41) |
e
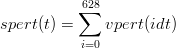 | (1.42) |
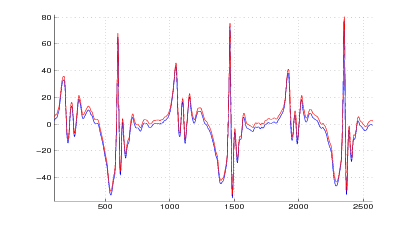
Il risultato di queste integrazione è confrontabile in figura 1.14; la deriva della seconda
integrazione non è trascurabile rispetto al valore dell’integrale.
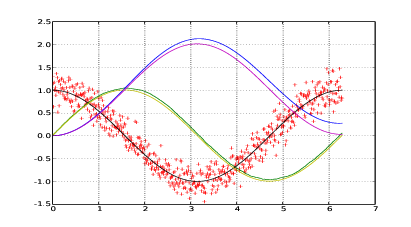
L’applicazione di un semplice smoothing a finestra scorrevole non sortisce effetti sul
risultato delle derive, ma rende l’andamento della funzione più comprensibile all’occhio
umano. La mediazione di un gruppo di valori infatti non fa altro che una somma parziale,
ovvero svolge una parte del lavoro che sarebbe stato svolto dal processo di integrazione. Ad
esempio, applicando lo smoothing descritto nel listato 1.2 (dove si definiscono le
funzioni asmooth(t),vsmooth(t),ssmooth(t) come accelerazione perturbata
sottoposta allo smoothing, prima e seconda integrazione della funzione asmooth(t))
sulla seconda integrazione si ottiene praticamente la stessa deriva che si sarebbe
ottenuto integrando il segnale originale sporco, come è ben evidente in figura
1.15.
Si supponga di avere a disposizione un modello che sia in grado di prevedere, entro un certo margine di errore, l’andamento dell’accelerazione nel tempo. Si può allora costruire un filtro di Kalman che operi sull’accelerazione a partire dalla previsione e dai dati misurati considerando:
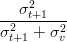 ;
;
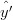 t+1 = ŷt+1 + Kt+1(xt+1 −ŷt+1) l’output del filtro;
t+1 = ŷt+1 + Kt+1(xt+1 −ŷt+1) l’output del filtro;Queste equazioni sono implementate nel listato 1.3, e il risultato ottenuto è mostrato in figura 1.16; il segnale filtrato dopo l’integrazione presenta una deriva visibilmente minore rispetto a quella dell’integrazione del segnale originario. Bisogna però tenere di conto che il filtro si avvale di informazioni più raffinate che un metodo per lo smoothing non usa, e che queste informazioni nella pratica delle misure accelerometriche spesso non sono disponibili.
Filtro di Kalman bidimensionale In [16] viene presentato un modello del filtro di Kalman che ingloba la doppia integrazione direttamente all’interno del filtro. Si prendano in considerazione le equazioni di stato (1.23) e di uscita (1.24) del filtro di Kalman, cambiando leggermente la notazione per comodità:
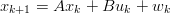 | (1.43) |
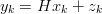 | (1.44) |
ovvero si indica con x lo stato del processo, u l’input (accelerazione), y l’output
(posizione), w,z i rumori rispettivamente sul processo e sulla misura.
Ponendosi nel caso discreto, ovvero nell’ipotesi che i parametri del moto (accelerazione e
posizione) siano aggiornati ogni t secondi, il moto del corpo è descritto dalle
equazioni:
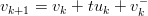 | (1.45) |
per quanto riguarda la velocità, dove vk− rappresenta il rumore sul processo 2, e:
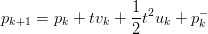 | (1.46) |
rappresenta la posizione; come prima pk− è il rumore sulla posizione.
Si può quindi definire il vettore di stato x in questo modo:
![[ ]
pk
x = vk](tesi75x.png) | (1.47) |
le matrici:
![[ ] [ 2 ] [ ]
A = 1 t , B = t∕2 , H = 1 0
0 1 t](tesi76x.png) | (1.48) |
il rumore sul processo wk ha una componente per lo spazio e una per la velocità:
![[ ]
p−k
wk = v−
k](tesi77x.png) | (1.49) |
La (1.43) diventa:
![[ ] [ ] [ 2 ] [ t2- − ]
xk+1 = pk+1 = 1 t xk + t ∕2 uk + wk = pk + tvk + 2 uk +− p k
vk+1 0 1 t vk + tuk + vk](tesi78x.png) | (1.50) |
e la (1.44):
![[ ]
yk = 1 0 xk + zk = pk + zk.](tesi79x.png) | (1.51) |
Rimangono da definire le covarianze dei rumori di processo e di misura:
![( [ (p−)2 p− v− ])
Sw = E (wkwTk) = E −k − k− k2
pk vk (vk )](tesi80x.png) | (1.52) |
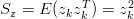 | (1.53) |
Le equazioni del filtro si possono esprimere nella forma:
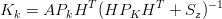 | (1.54) |
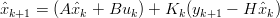 | (1.55) |
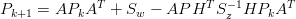 | (1.56) |
La matrice Pk, che rappresenta la covarianza stimata dell’errore di processo, viene
inizializzata utilizzando le uniche informazioni note, ovvero P0 = Sw; anche 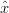 0 viene
inizializzato allo stato iniziale del processo.
0 viene
inizializzato allo stato iniziale del processo.
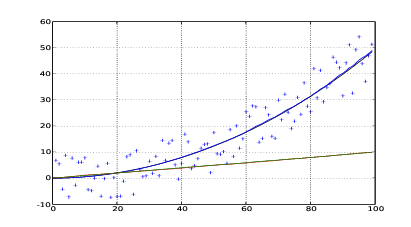
Si consideri il caso di un’automobile che si muove con accelerazione costante: si effettuano
misure di posizione periodiche affette da un errore grande e si considera che l’accelerazione
reale che il veicolo subisce non è esattamente costante ma è affetta da fluttuazioni dovute
a condizioni fisiche quali vento o asperità dell’asfalto. Il risultato dell’applicazione del filtro
bidimensionale a questo semplice esempio è mostrato in figura 1.17; nonostante le misure
spaziali siano molto imprecise il risultato del filtro è molto vicino alla posizione reale
dell’automobile.
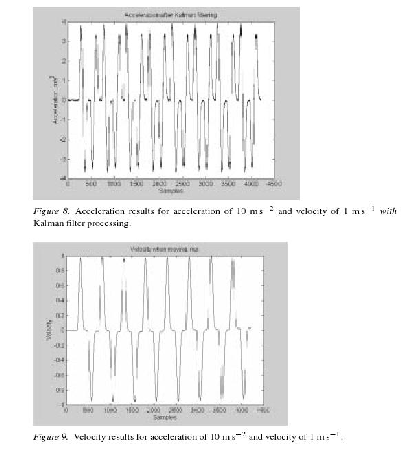
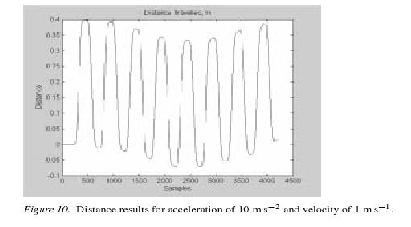
In [5] e in [13] viene studiato il comportamento di un accelerometro sottoposto a
movimenti precisi eseguiti da un braccio meccanico. Per la riduzione del rumore viene usato
un filtro di Kalman, modellato per svolgere esso stesso il processo di integrazione in
cascata. L’accelerometro è stato sottoposto a tre cicli di spostamento assiale, ogni volta
con la stessa accelerazione; questa prova è stata fatta con tre accelerazioni differenti. I
problemi riscontrati sono la scelta del bias e l’accumulazione degli errori nel processo di
integrazione. In particolare l’accuratezza della misura del bias si è rivelata particolarmente
importante per le misure con l’accelerazione più bassa, dove anche le fluttuazioni naturali
dovute alla temperature ed altri fattori ambientali; per ognuno dei tre cicli è stato
ricalcolato un bias diverso. Nelle prove con accelerazione maggiore il problema
del bias è meno rilevante, e sono state raggiunte precisioni sulla misura spaziale
nell’ordine del centimetro. In particolare Liu e Pang hanno sottoposto l’accelerometro
a spostamenti assiali eseguiti da un braccio meccanico; ogni spostamento ha
velocità e accelerazione massime ben note, ed è un movimento del tipo andata e
ritorno al punto di partenza. Nelle figure 1.18 e 1.19 viene mostrato il risultato
che hanno ottenuto utilizzando un filtro di Kalman ma nell’articolo non viene
spiegato nei dettagli come questo viene modellato; i risultati che hanno ottenuto non
sono molto distanti da quelli ottenuti con i metodi descritti in sezione 1.1.2.
Il filtro che viene utilizzato in questo articolo non viene descritto nei dettagli,
quindi non è stato possibile implementarlo per fare un confronto diretto con altri
metodi più semplici ma che in questo contesto sembrano altrettanto efficaci.
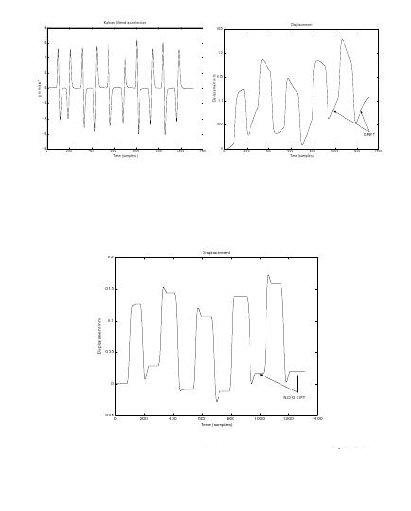
In [14] vengono studiati e realizzati dei controllori accelerometrici destinati all’interazione
con i wearable computers. In particolare sono stati realizzati una penna utile per il
puntamento, un tilt pad che rileva i movimenti di un piano utilizzabile in contesti di mixed
reality come ad esempio la cartografia 3D, e un gesture pad da portare al polso
utilizzabile, ad esempio, per la selezione di comandi tramite gesti. Per la riduzione del
rumore e l’integrazione viene usato un filtro di Kalman ma i problemi dovuti
allo spostamento naturale del bias dell’accelerometro non sono trascurabili. Si
tenta di mitigare questo problema considerando il tasso massimo di cambiamento
dell’accelerazione (che per motivi fisici è limitato) inglobandolo nel modello del filtro; in
particolare vengono considerati due limiti diversi rispettivamente per lo stato
di quiete del sensore e per lo stato di moto (nel primo caso il rate massimo è
molto minore). In questo caso il metodo è stato provato su un movimento di
andata e ritorno monoassiale imposto all’accelerometro manualmente e non da un
braccio meccanico. Le accelerazioni (grafico in altro a sinistra in figura 1.20) non
sono così precise e uniformi come quelle che hanno avuto a disposizione Liu e
Pang. I risultati dell’applicazione di questo metodo sono mostrati in figura 1.20;
il risultato finale è una precisione intorno ai 10cm iniziale migliorata a 2.5cm,
inglobando come invariante l’inclinazione massima della curva dell’accelerazione nel
filtro.
La caratteristica fondamentale dei moti bidimensionali di un corpo rigido, rispetto a quelli
monodimensionali, è di avere due gradi di libertà in più: uno è ovviamente la dimensione
spaziale aggiuntiva, l’altra è la possibilità di ruotare il sistema di riferimento. Lavorare su
assi che non subiscono rotazioni non è un problema: nella maggior parte dei casi si possono
considerare singolarmente gli assi come se fossero due moti unidimensionali separati;
in molti contesti si possono usare i dati di un asse per porre vincoli sull’altro e
viceversa.
Il caso in cui gli assi dell’accelerometro ruotino rispetto al sistema di riferimento è invece
più complicato da trattare. Intuitivamente, nel caso di movimenti generici non
esiste un modo per ricavare l’angolo di rotazione dalle misure lungo due assi: una
semplice rotazione del sensore sul suo asse non è rilevabile, e anche nel caso
fortuito in cui il sensore sia in una posizione che permette di misurare la forza di
gravità terrestre (in questo caso una rotazione produce una modifica della misura
contemporaneamente sui due assi) non c’è modo per distinguere la variazione di
accelerazione dovuta alla rotazione da quella dovuta al movimento assiale del
sensore.
Il problema della rotazione del sensore è aggirabile nel caso di movimenti semplici, dei quali si conosca il tipo di rotazione a cui è soggetto l’accelerometro e si sia in grado di identificare facilmente l’inizio e la fine del movimento. Un esempio concreto è la misura di movimenti che si svolgono lungo archi di circonferenza, come il movimento di un braccio meccanico o la flessione di un arto quali spalla e ginocchio; in questo caso particolare i dati che forniscono informazione utile sono l’accelerazione tangenziale e radiale.
Il moto a cui è sottoposto il sensore si può descrivere agevolmente in termini relazioni angolari ed è ben approssimato dalla relazione:
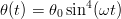 | (1.57) |
dove la pulsazione si ricava dal tempo di esecuzione del movimento secondo la relazione ω = 2π∕T. La velocità e l’accelerazione angolari sono esprimibili come:
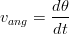 | (1.58) |
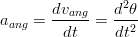 | (1.59) |
z Le accelerazioni tangenziale (at) e radiale (ar), ovvero le grandezze che si possono di misurare direttamente, sono in relazione diretta con l’angolo θ e il raggio della circonferenza ρ:
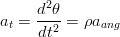 | (1.60) |
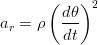 | (1.61) |
Se il piano in cui si effettuano le misure è perpendicolare alla superficie terrestre, su ognuno dei due assi si riscontra una componente dell’accelerazione gravitazionale che dipende direttamente dall’angolo θ:
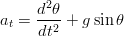 | (1.62) |
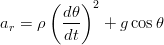 | (1.63) |
si può quindi distinguere la componente gravitazionale dal dato utile per la misura.
Per risalire alla velocità tangenziale si può, formalmente, sfruttare l’equazione della derivata
di ar:
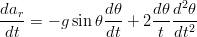 | (1.64) |
Ricavando 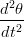 dalla misura di at:
dalla misura di at:
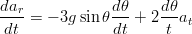 | (1.65) |
si ottiene infine:
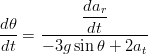 | (1.66) |
Questa equazione non è adatta al calcolo, in quanto il termine al denominatore passa da zero e la sua integrazione porta a delle instabilità numeriche non banali; si può però procedere a un’integrazione numerica diretta dell’equazione del secondo ordine:
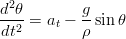 | (1.67) |
con il metodo descritto nel listato 1.4, basato sul metodo di Eulero.
Il gait cycle1 , può, a fini di studio, essere considerato suddiviso in tre periodi principali:
Con stance si indica il periodo di tempo in cui il piede è in contatto con il terreno, fase
che dura più del 60% del tempo totale; lo swing è il periodo in cui il piede è sollevato da
terra e questa fase dura circa il 30% del tempo. Infine la fase di double support si ha
quando entrambi i piedi sono in contatto con il terreno, cosa che accade due volte per ogni
gait cycle; questa fase dura circa il restante 10% del tempo ma la sua durata diminuisce
con il velocizzarsi dell’andatura: durante la corsa i piedi non sono mai entrambi in contatto
con il terreno contemporaneamente.
In generale, si riescono ad individuare varie fasi della camminata ben distinte nel
tempo:
Le fasi 1,2,3,4,5 compongono il periodo di stance, mentre il periodo di swing è essenzialmente
composto dalle fasi 6,7,8. La fase 5 è quella in cui la gamba viene preparata dal busto
all’oscillazione.
Il contatto iniziale (1) è un evento istantaneo nel tempo e si verifica quando il
piede della gamba guida tocca il terreno. Dal punto di vista del piede questo è un
evento relativamente violento; è quindi ragionevole supporre che possa essere
facile rilevarlo a partire dalle misure accelerometriche effettuate all’altezza della
caviglia.
Durante la fase di risposta al carico (2) il piede viene gradualmente messo in contatto con
il terreno ed il peso del corpo viene spostato su di esso quando il contatto diventa
completo; è in questo momento che comincia il passo vero e proprio inteso come
movimento del corpo.
Le altre fasi consistono tutte di movimenti dolci e quindi sicuramente non semplici da
individuare in maniera precisa con gli strumenti che si hanno a disposizione. L’attenzione
dovrà quindi essere concentrata sull’individuazione del punto di contatto del piede con il
terreno e sull’inizio della fase di risposta al carico la quale, dai punti di vista spaziale e
temporale, costituisce la vera fine del passo (e inizio del passo successivo) ovvero è la fase
più significativa al fine della misurazione.
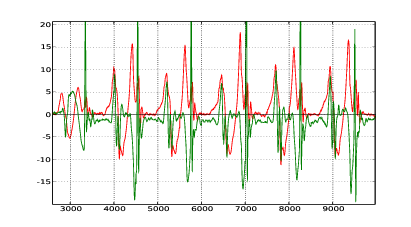
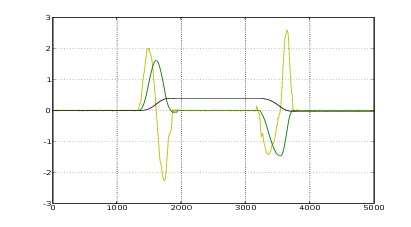
I segnali accelerometrici che si ottengono dall’acquisizione di una camminata sono piuttosto chiari, un esempio è mostrato in figura 2.1. Il momento del contatto del tallone col terreno è ben evidente dal tracciato delle accelerazioni lungo la direzione del moto, ci sono dei picchi marcati e di breve durata. Questi picchi non sono così tanto marcati in caso di camminate particolarmente leggere, ma comunque si è in grado di distinguere il momento dell’appoggio del tallone. Questa fase della camminata è importante perché permette di fissare dei vincoli sul calcolo degli spostamenti: quando il piede è a terra la sua velocità è nulla e la posizione sull’asse caviglia-ginocchio2 è quella iniziale. In figura 2.2 si vede un esempio di individuazione dei punti di appoggio e quindi dei vari passi (intervalli tra un appoggio e l’altro); numericamente questo viene implementato con una ricerca sui picchi maggiori di una certa soglia, che a sua volta viene definita in base al valore massimo che si rileva su questo asse. I punti individuati in questo modo non corrispondono ancora esattamente al momento in cui il piede è completamente appoggiato a terra e fermo ma corrispondono al momento in cui il tallone tocca terra. Il piede quindi deve ancora terminare la sua rotazione ma dal segnale non si riesce ad individuare facilmente il momento in cui questo succede. Nella pratica questo richiede un tempo breve e quasi costante (anche se cambia in funzione della velocità a cui si sta camminando, ovvero della frequenza dei passi): considerando il movimento di durata costante e scegliendo un valore ragionevole per la durata si ottengono comunque buoni risultati.
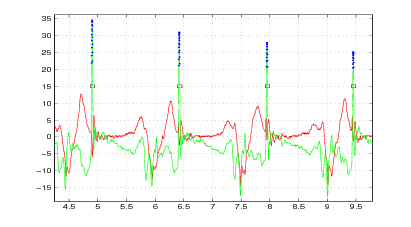
La possibilità di determinare il momento di appoggio del piede permette di sfruttare le informazioni che sono note circa quell’istante:
Più formalmente, indicando con tin e tfn il momento di inizio e di fine del passo n−esimo, il vincolo sulle velocità può essere espresso come:
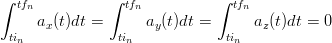 | (2.1) |
e quello sugli spazi:
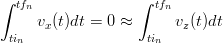 | (2.2) |
La posizione laterale del piede (asse z) è soggetta ad oscillazioni da un passo all’altro, ma
mediamente rimane intorno alla posizione iniziale; si ritiene sensato quindi considerare
comunque nulla l’oscillazione.
In generale, a causa degli errori di misura e delle successive derive delle integrazioni, indipendentemente dall’asse che si stia considerando si ha una situazione del tipo:
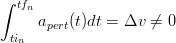 | (2.3) |
e quindi anche:
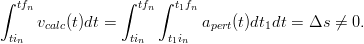 | (2.4) |
Il vincolo sull’integrazione può essere imposto modificando la funzione da integrare; in particolare si cerca una funzione φ(t) tale che:
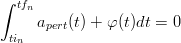 | (2.5) |
e
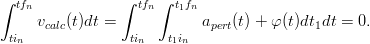 | (2.6) |
Un modo per scegliere la funzione φ(t) è quello di considerarla come somma pesata di due funzioni:
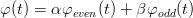 | (2.7) |
di cui una è pari e definita positiva e l’altra è dispari a media nulla.
Una delle coppie di funzioni che assolvono questo scopo, semplice da trattare nell’intervallo
[tin,tfn] è:
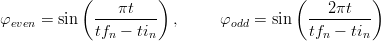 | (2.8) |
Il coefficiente α può essere ricavato direttamente dall’equazione:
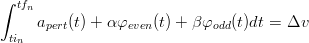 | (2.9) |
in quanto l’integrale della funzione dispari nell’intervallo [tin,tfn] è nullo, e β conseguentemente può essere ricavato dal secondo vincolo:
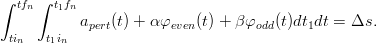 | (2.10) |
Si ha quindi che:
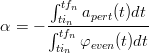 | (2.11) |
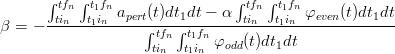 | (2.12) |
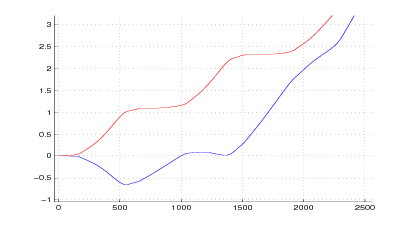
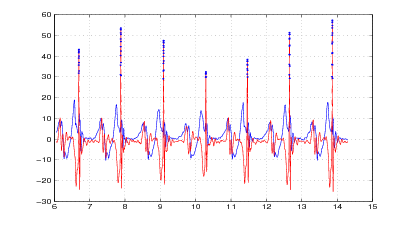
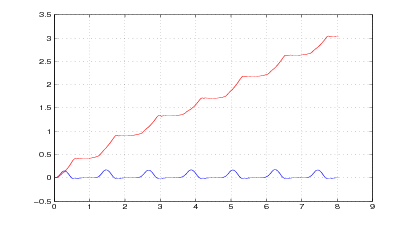
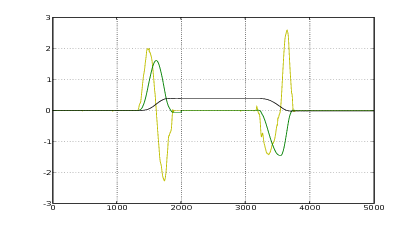
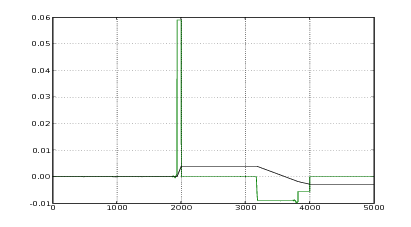
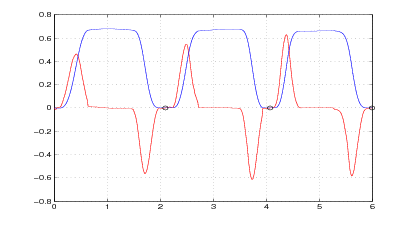
Nelle figure 2.3 e 2.4 si vede il risultato del metodo appena descritto applicato ad una
misura reale. Nelle figure 2.5 e 2.6 invece si confronta il risultato della successiva doppia
integrazione: mentre l’integrazione del segnale originale non dà luogo a risultati
apprezzabili, l’integrazione del segnale corretto fornisce risultati apprezzabilmente
precisi.
Un limite di questo metodo subito evidente già dalle prime sperimentazioni risiede nella
scelta, in parte arbitraria, del punto di fermo del piede: uno spostamento anche di soli 50
millisecondi origina risultati visibilmente diversi. Questo fatto rende obbligatoria una scelta
del punto di fermo calibrata in base alla camminata che si sta misurando: una
camminata con passi veloci ha logicamente il punto di fermo più vicino (nel tempo)
all’appoggio del tallone rispetto a una camminata lenta con falcate piuttosto
lunghe.
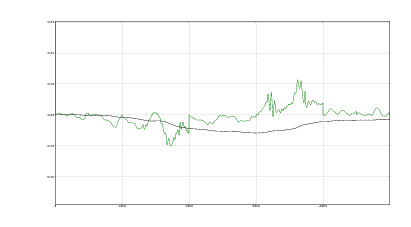
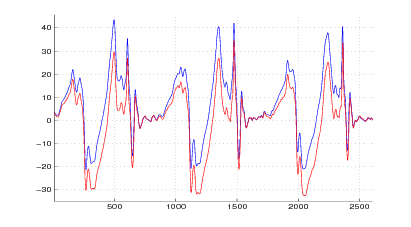
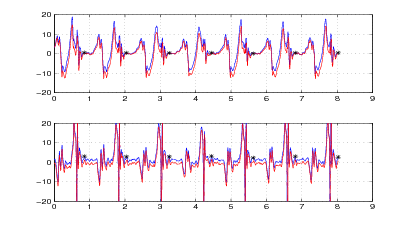
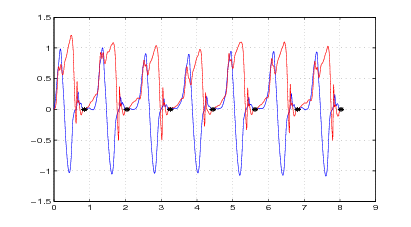
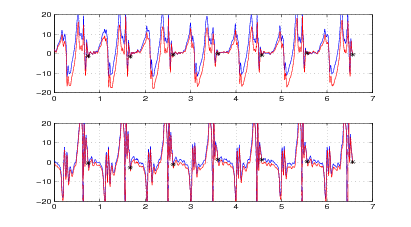
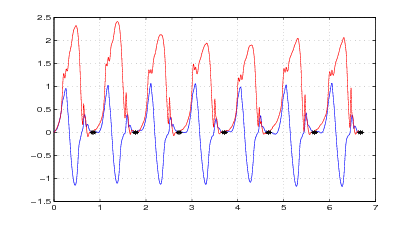
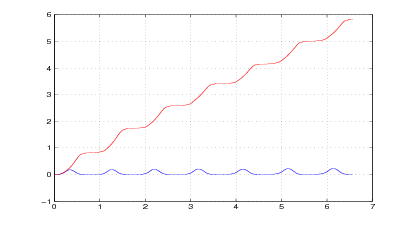
Nelle figure 2.7 e 2.8, 2.9 e 2.10 si mostrano i risultati che si ottengono applicando il
metodo a due acquisizioni di due camminate distinte.
È molto interessante notare, nel grafico delle velocità, delle oscillazioni che si verificano
lungo l’asse y prima della fine del passo, in corrispondenza con la fine della fase di
sollevamento del piede; queste oscillazioni sono presenti in tutte le acquisizioni che sono
state fatte, e rispecchiano una caratteristica, evidentemente presente ma inaspettata, della
camminata.
La correzione notevole che si ha come offset sull’asse x è dovuta alla rotazione della
caviglia, la quale fa sì che il sensore misuri in parte l’accelerazione gravitazionale; si
noti a tal proposito che la correzione in prossimità dei punti di fermo è quasi
nulla.

.
Il sistema GPS (Global Positioning System) è un apparato costituito di satelliti in orbita e ricevitori a terra che permette all’utente di localizzarsi in ogni parte del globo terrestre. Al momento della progettazione furono decisi alcuni requisiti minimi che il sistema deve soddisfare al fine di assicurarne l’utilità pratica:
Questi requisiti, unitamente alla disponibilità delle bande di frequenza, collocano la portante del segnale GPS nella zona bassa delle microonde, ovvero tra uno e due Ghz.
L’idea che sta alla base del sistema GPS si basa sul fatto che è possibile, dati tre punti di
riferimento nello spazio tridimensionale, conoscere la posizione relativa a questi di un
quarto punto.
Siano r1,r2,r3, di coordinate rispettivamente (x1,y1,z1), (x2,y2,z2), (x3,y3,z3), i punti di
riferimento con coordinate note; si può allora facilmente identificare le distanze di
questi punti dal nostro punto incognito ru = (xu,yu,zu) grazie al teorema di
Pitagora:
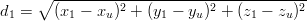 |
 |
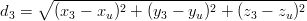 | (3.1) |
Il segnale emesso dai satelliti permette di misurare le distanze (d1,d2,d3) nello stesso istante di tempo (come si vedrà in seguito); quindi si ha un sistema di tre equazioni in tre incognite per cui esiste soluzione e che permette di localizzare il punto ru nello spazio.
Misura delle distanze Ogni satellite emette un segnale all’istante tsi che verrà ricevuto più tardi dall’utente all’istante tu. Le onde elettromagnetiche viaggiano alla velocità della luce e questo permette di definire la distanza dal satellite come:
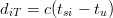 | (3.2) |
Nella pratica è quasi impossibile ottenere un corretto riferimento temporale dal satellite o dall’utente: il tempo reale del satellite (tsi′) e quello reale dell’utente (tu′) si possono considerare legati al tempo esatto secondo le relazioni:
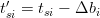 | (3.3) |
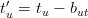 | (3.4) |
dove Δbi è l’errore sull’orologio del satellite mentre but è l’errore dell’orologio del ricevitore,
espresso sotto forma di bias.
Oltre agli errori di tempo ci sono altri fattori che influenzano la misura della distanza,
quali:
La distanza dal satellite (chiamata pseudorange) deve quindi essere espressa come:
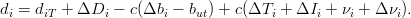 | (3.5) |
Alcuni di questi errori posso essere corretti: il ritardo troposferico ad esempio può
essere modellato, mentre quello ionosferico può essere corretto con un ricevitore
multifrequenza.
Il tempo reale del ricevitore rimane però un’incognita; il sistema di distanze, affinché abbia
soluzione, deve essere espanso a quattro equazioni:
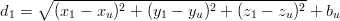 |
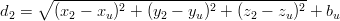 |
 |
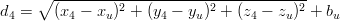 | (3.6) |
dove bu è l’errore di bias sul tempo dell’utente espresso in distanza, che vale
bu = cbut.
Sono quindi necessari almeno quattro satelliti per poter calcolare la posizione attuale
dell’utilizzatore.
Calcolo della posizione in assenza di errori
Per brevità si indica con dr la distanza dal satellite, con (xr,yr,zr) le coordinate (note)
del satellite ma con (X,Y,Z) quelle dell’utente; si ricordi che il sistema di coordinate è
centrato e fisso rispetto alla Terra.
Prendendo in considerazione solo una delle equazioni del sistema 3.1 si ottiene:
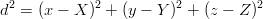 |
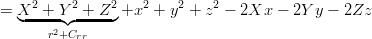 | (3.7) |
dove r è il raggio terrestre e Crr il bias di correzione dell’orologio. Si ottiene quindi:
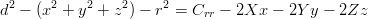 | (3.8) |
che è una equazione in quattro incognite.
Considerando contemporaneamente quattro satelliti si ottiene il sistema:
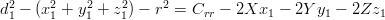 |
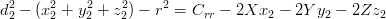 |
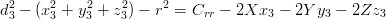 |
 | (3.9) |
che è risolvibile in questa forma:
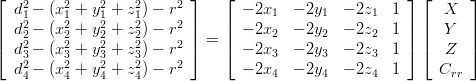 | (3.10) |
Calcolo della velocità dell’utente In questo caso si deve prendere in considerazione la variazione della posizione tra due misure successive:
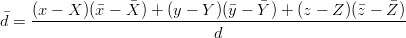 | (3.11) |
dove è il rate di cambiamento della distanza (conosciuto), (,,) è la velocità del satellite (conosciuto) e (,,) è la velocità dell’utente. Dalla 3.11 si ottiene direttamente:
![1
− ¯d + -[¯x(x − X ) + ¯y(y − Y ) + ¯z(z − Z )]
d](tesi148x.png) |
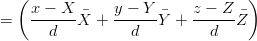 | (3.12) |
e il conseguente sistema di tre equazioni può essere risolto in questo modo:
![⌊ −d¯1 + -1 [x ¯1(x1 − X ) + ¯y1(y1 − Y) + ¯z1(z1 − Z)] ⌋
⌈ ¯ d11 ⌉
−d2 + d21 [x ¯2(x2 − X ) + ¯y2(y2 − Y) + ¯z2(z2 − Z)]
−d¯3 + d3 [x ¯3(x3 − X ) + ¯y3(y3 − Y) + ¯z3(z3 − Z)]](tesi150x.png) |
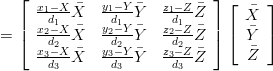 | (3.13) |
Coordinate sferiche
Per comodità si usa esprimere la posizione in coordinate sferiche (latitudine, longitudine
e altitudine), che è il sistema usualmente utilizzato in cartografia. È quindi necessario
convertire le coordinate cartesiane (xu,yu,zu) trovate nella soluzione del sistema di
equazioni 3.6.
La latitudine della Terra va da 90° a -90° con 0° all’equatore; la longitudine da 180° a
-180° con 0° sul meridiano di Greenwich; per altitudine si intende lo scostamento radiale
rispetto alla superficie della Terra.
Se la Terra fosse perfettamente sferica queste coordinate risulterebbero facili da ricavare
nel seguente modo.
La distanza dal centro della Terra vale:
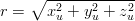 | (3.14) |
la latitudine:
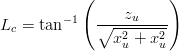 | (3.15) |
la longitudine:
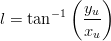 | (3.16) |
e infine l’altitudine:
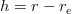 | (3.17) |
dove re rappresenta un ideale raggio medio terrestre.
In realtà la Terra non è né sferica né tantomeno liscia; in realtà le coordinate vengono
ricavate su un modello geodetico chiamato WGS84 (World Geodetic System),
che è lo standard internazionale per le coordinate di navigazione rilasciato nel
1984.
Scelta dei satelliti Generalmente un ricevitore GPS in regime di funzionamento può ricevere, simultaneamente, i segnali di un numero compreso tra 4 (minimo indispensabile) e 11 satelliti. Sotto queste condizioni ci sono almeno due strategie che si possono utilizzare:
Generalmente l’approccio adottato è il primo, che ha il vantaggio di riuscire a ottenere una
precisione migliore ma che ha bisogno di più potenza di calcolo.
Nel secondo caso l’idea è di scegliere la combinazione di satelliti che massimizza il volume
del solido che ha i satelliti stessi come vertici.
Questa semplice proprietà massimizza l’angolo di incidenza delle sfere di segnale emesse dai
satelliti e permette un’accurata misura della posizione; infatti tanto più piccolo è l’angolo di
incidenza tra le sfere (ovvero i satelliti coprono un angolo più acuto se guardati dal punto di
utilizzo), tanto più i bordi delle sfere che passano per il punto di utilizzo saranno tangenti,
rendendo meno accurata la misura.
Orbite
Il sistema GPS consta di 24 satelliti (28 dal marzo 2006) attivi, distribuiti
uniformemente su sei orbite circolari con quattro satelliti ciascuna. Le orbite sono inclinate
di 55° rispetto all’equatore e tra loro di multipli di 60°; sono approssimativamente circolari,
non geostazionarie, con un raggio di 26560 km e un periodo di rivoluzione di mezzo giorno
siderale (circa 11,967 ore).
Teoricamente questa disposizione permette contemporaneamente la visibilità di tre o più
satelliti in quasi ogni punto della superficie terrestre a qualsiasi ora del giorno o della
notte.
Segnali
Ogni satellite trasporta quattro orologi atomici, due al cesio e due al rubidio,
che forniscono le informazioni di temporizzazione necessarie alla trasmissione dei
segnali.
È in funzione un sistema di correzione automatica degli orologi assistito dalle stazioni di
controllo a terra, che effettua correzioni periodiche. I satelliti trasmettono due
segnali (L1,L2), il primo con portante a f1 = 1, 57543 Ghz e l’altro f2 = 1, 2276
Ghz, che sono multipli interi di una frequenza base comune di f0 = 1023 Mhz
(f1 = 1540f0,f2 = 1200f0). Entrambi trasmettono un segnale codificato in BPSK (binary
phase shift keying); il primo è modulato da due pseudorandom codes (PRN), l’altro solo
dal secondo PRN. Il segnale L1 viene trasmesso a un livello minimo di 478.63W (26,8dBW)
EIRP (Effective Isotropic Radiated Power), il che significa che il ricevitore a terra riceve un
segnale equivalente a quello che avrebbe ricevuto se fosse stato trasmesso da un’antenna
isotropica a quella potenza.
In realtà viene emessa una potenza minore su un cono con angolo al vertice di circa 30°
diretto verso la Terra. Il segnale, mentre si propaga verso la Terra, perde densità di potenza
a causa della propagazione sferica.
La perdita può essere quantificata con il free-space loss factor (FSLF):
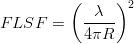 | (3.18) |
dove λ è la lunghezza d’onda del segnale e R la distanza dall’antenna.
Il FSLF indica la densità frazionaria di potenza ad una distanza di R metri dall’antenna
comparata col valore normalizzato unitario λ∕4π metri dal centro di fase dell’antenna.
Considerando quindi un satellite in orbita a 2 × 107m di quota e un segnale con lunghezza
d’onda λ = 0.19m, il FSLF vale 5.7 × 10−19, ovvero −182.4dB.
Effetto Doppler
All’atto della ricezione del segnale da parte dell’utilizzatore si presenta un altro
problema: la frequenza a cui i segnali arrivano non è la stessa a cui sono stati emessi; essa
viene percepita aumentata o diminuita a seconda che il satellite si stia avvicinando oppure
allontanando. Occorre quindi che il ricevitore sia in grado di aggiustare la propria frequenza
di ricezione in funzione di questa situazione.
La velocità angolare del satellite può essere calcolata facilmente sapendo il tempo esatto di
rivoluzione:
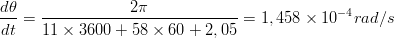 | (3.19) |
e la velocità periferica:
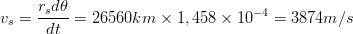 | (3.20) |
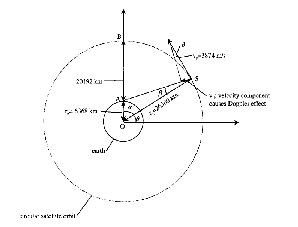
L’effetto Doppler è causato dalla velocità periferica del satellite rispetto all’utente, che, riferendosi alla figura 3.1, vale:
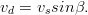 | (3.21) |
Esprimendo la velocità in termini di angolo θ, utilizzando il teorema di Pitagora:
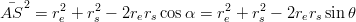 | (3.22) |
quindi:
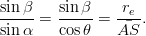 | (3.23) |
Utilizzando quest’ultimo risultato all’interno della 3.21:
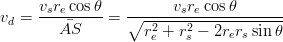 | (3.24) |
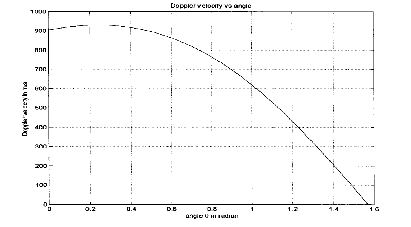
Questa velocità può essere disegnata al variare di θ come si vede in figura 3.2.
Quando il satellite è allo zenit rispetto all’utente, la componente della velocità che causa
l’effetto Doppler è zero.
L’angolo in cui l’effetto Doppler è massimo si può trovare derivando vd rispetto all’angolo
θ, trovando il massimo della funzione vd, che risulta essere:
 | (3.25) |
Per questo valore di θ il satellite risulta essere all’orizzonte della visuale dell’utente.
Con questi dati possiamo calcolare la velocità massima di Doppler vdm, che lungo la
direzione orizzontale vale:
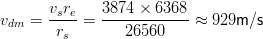 | (3.26) |
che è una velocità piuttosto elevata. Lo spostamento di frequenza risulta valere, nel caso del segnale L1:
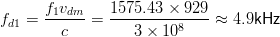 | (3.27) |
Generalmente l’effetto Doppler causato dal movimento dell’utente è trascurabile, a meno che non si tratti di velivoli ad alta velocità (500 km/h o più).
Il problema della misura del tempo
Per determinare la propria posizione il ricevitore GPS deve misurare il tempo che il
segnale impiega a viaggiare dal satellite alla Terra: le coordinate spaziali della posizione del
satellite sono codificate nel segnale stesso; quindi l’unica incognita rimane la distanza
lineare satellite-ricevitore.
Nella pratica il modo più semplice per ottenere questa misura è avere due orologi
perfettamente sincronizzati, uno a terra e l’altro sul satellite, e confrontare l’istante in cui il
segnale viene ricevuto con l’istante in cui è stato mandato, informazione codificabile nel
segnale stesso.
La misura di tempo effettuata all’interno del satellite, quella cioè che marca il segnale
trasmesso, può ritenersi sostanzialmente esente da errori: gli orologi a bordo hanno una
precisione superiore al nanosecondo (un secondo è definito come la durata di 9.192.631.770
periodi della radiazione corrispondente alla transizione tra due livelli iperfini dello stato
fondamentale dell’atomo di cesio-133), e un segnale radio in un nanosecondo
percorre circa: 3 × 108 × 1 × 10−9 = 3 × 10−1 metri, che è un errore più che
accettabile.
I ricevitori a terra presentano invece problemi aggiuntivi: non è pensabile utilizzare un
orologio atomico in ricezione, che è pesante, voluminoso e molto costoso; bisogna quindi
accontentarsi di orologi meno precisi. Fino a quale precisione si può scendere?
Un orologio con precisione al microsecondo risulterebbe quasi inutile, in quanto in questo
caso l’errore salirebbe a circa 3 × 108 × 1 × 10−6 = 3 × 102 metri. Per ottenere un errore
nell’ordine del metro ci vuole una precisione che arrivi almeno a 1∕(3 × 108) = 0.4 × 10−8
secondi.
L’errore di bias sulla sincronizzazione non è problematico quando si hanno a disposizione i
segnali di quattro satelliti (ovvero il sistema 3.9 ha soluzione esatta); bisogna invece porre
particolare attenzione ad altri fattori, quali la risoluzione, la marcia e la deriva.
Per marcia si intende la differenza di velocità rispetto a un altro orologio, ovvero il numero
di secondi che guadagna o perde ogni giorno; per deriva si intende la stabilità nel tempo
della marcia. Nel caso di un ricevitore GPS l’errore di marcia è compensabile insieme a
quello di bias (tutti i satelliti hanno uno stesso errore costante sulla misura del tempo e
l’errore di marcia va quindi a sommarsi all’errore di bias), mentre quello di deriva è più
deleterio in quanto aggiunge un fattore che varia casualmente in base alle condizioni di
lavoro istantanee.
Gli effetti della relatività La teoria della relatività speciale è basata su due postulati fondamentali:
Si prenda in considerazione un esperimento che consiste nell’inviare un raggio di luce verso uno
specchio e leggere il tempo che impiega a tornare indietro.
Si indica con Δl la distanza tra l’emettitore e lo specchio. In un sistema di riferimento
fermo rispetto all’apparecchiatura dell’esperimento, la luce compie un percorso pari
a 2 × Δl in un tempo Δt = 2Δl∕c. Supponiamo invece che l’esperimento sia
condotto a bordo di un treno che si muove a velocità uniforme e ci si ponga in un
sistema di riferimento stazionario rispetto alla Terra. Dal nostro punto di vista il
raggio di luce compie una traiettoria obliqua, quindi la distanza tra l’emettitore
e lo specchio vale Δl2 = 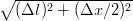 dove Δx indica lo spostamento
longitudinale del treno rispetto all’osservatore, e chiaramente Δl2 è maggiore di Δl. La
velocità della luce è però costante per tutti e due i sistemi di riferimento, quindi
nel secondo sistema l’esperimento deve durare un tempo Δt2 = 2Δl2∕c > Δt.
Considerando che Δx = vΔt, dove v è la velocità a cui si muove il treno, si
ottiene:
dove Δx indica lo spostamento
longitudinale del treno rispetto all’osservatore, e chiaramente Δl2 è maggiore di Δl. La
velocità della luce è però costante per tutti e due i sistemi di riferimento, quindi
nel secondo sistema l’esperimento deve durare un tempo Δt2 = 2Δl2∕c > Δt.
Considerando che Δx = vΔt, dove v è la velocità a cui si muove il treno, si
ottiene:
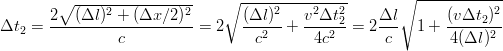 |
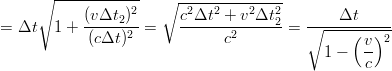 | (3.28) |
ovvero l’osservatore fermo percepisce l’evento con una durata dilatata in funzione della velocità a cui si muove l’altro sistema. Se si moltiplica la 3.28 per c si ottiene:
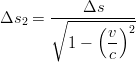 | (3.29) |
dove Δs e Δs2 sono i tratti percorsi dalla luce nei due sistemi di riferimento. Questo
risultato indica che, insieme ai tempi, si dilatano anche le lunghezze.
Si consideri adesso un segnale elettromagnetico, per il quale vale la relazione c = λf. Grazie all’equazione 3.29 sappiamo che λ può risultare diverso a seconda del sistema di riferimento; se si pone λ = Δs e λ2 = Δs2 si ottiene:
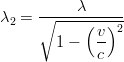 | (3.30) |
e dividendo per c:
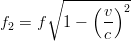 | (3.31) |
ovvero il sistema fermo riceve un segnale a una frequenza più alta di quella emessa nel
sistema in movimento.
Se si considerano velocità piccole rispetto a quella della luce si posso utilizzare le espansioni
in serie di Taylor:
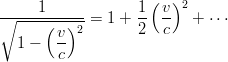 | (3.32) |
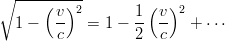 | (3.33) |
che consentono di ottenere:
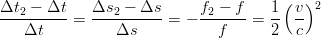 | (3.34) |
L’espressione 
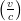 2 può anche essere letta come l’energia cinetica per unità di massa (
2 può anche essere letta come l’energia cinetica per unità di massa (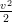 )
scalata di un fattore
)
scalata di un fattore 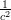 , ovvero gli effetti della relatività speciale possono essere interpretati
come gli effetti causati dall’energia cinetica del moto. Effetti analoghi potrebbero anche
essere causati dall’energia potenziale ΔU dovuta alla presenza di un campo gravitazionale
U. Vale quindi:
, ovvero gli effetti della relatività speciale possono essere interpretati
come gli effetti causati dall’energia cinetica del moto. Effetti analoghi potrebbero anche
essere causati dall’energia potenziale ΔU dovuta alla presenza di un campo gravitazionale
U. Vale quindi:
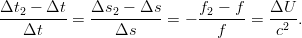 | (3.35) |
L’effetto relativistico totale può essere quindi espresso come:
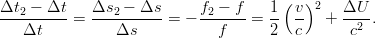 | (3.36) |
Gli effetti della relatività sul sistema GPS non possono essere ignorati a causa
dell’elevata velocità periferica dei satelliti, della differenza di campo gravitazionale non
trascurabile e della rotazione della Terra. Per studiarne gli effetti generalmente si considera
come sistema di riferimento quello stazionario con centro coincidente con il centro della
Terra.
L’effetto diretto più importante che si riscontra è lo spostamento delle frequenze
dovuto alla velocità relativa tra i satelliti e il ricevitore ed al campo gravitazionale
terrestre.
La frequenza percepita dall’utente (f2) è quindi diversa da quella trasmessa dal satellite
(f); per questo motivo occorre correggere il segnale emesso dal satellite affinché l’utente
percepisca la frequenza di 1023MHz come da specifica.
È noto che:
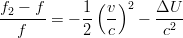 | (3.37) |
dove v è la velocità del satellite e ΔU la differenza di potenziale gravitazionale tra la quota
dell’utente e quella del satellite.
Si può quindi esprimere il potenziale gravitazionale come:
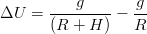 | (3.38) |
dove R ≈ 6370km è il raggio della Terra, H ≈ 20200km l’altitudine del satellite (rispetto al
suolo) e g la costante gravitazionale terrestre.
Il satellite deve quindi trasmettere a una frequenza pari a 1023 − 4.57 × 10−9
MHz.
Anche il ricevitore deve però calcolare il proprio offset di frequenza allo stesso modo,
considerando il campo gravitazionale nullo e velocità pari a quella periferica della
Terra.
In letteratura si riscontra un notevole interesse alle possibili applicazioni dei sistemi INS
(Inertial Navigation Systems). Questi sistemi, però, non hanno ancora riscosso successo
nella pratica proprio a causa dei problemi che sorgono al momento della estrapolazione
delle informazioni: l’accumulazione degli errori presenta problemi di non facile
soluzione.
Il sistema GPS ha il pregio di poter essere molto preciso: in condizioni ottimali si riesce a
ottenere un posizionamento con precisione dell’ordine del centimetro, ma tipicamente la
frequenza di acquisizione è bassa, nell’ordine di un’acquisizione al secondo. I sistemi INS
hanno invece il pregio di fornire una frequenza di acquisizione alta, nell’ordine del Khz, ma
la misura perde velocemente di precisione con il passare del tempo a causa delle
derive. Sembra pertanto sensato integrare i sistemi GPS con sistemi INS: mentre il
posizionamento satellitare assicura con cadenza regolare una misura precisa, il sistema
inerziale è in grado di fornire la risoluzione desiderata tra un campionamento GPS e
l’altro.
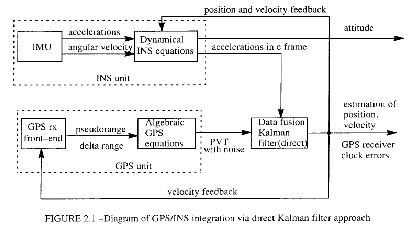
In [11] viene proposta una formulazione del filtro di Kalman appositamente studiata per
integrare il posizionamento GPS con misure accelerometriche. In particolare il segnale GPS
viene usato per ottenere i punti di misurazione mentre i segnali accelerometrici
contribuiscono al processo di predizione per il prossimo stato del filtro. In figura 3.3 viene
mostrato il ruolo proposto per il filtro di Kalman all’interno del sistema di processamento
dei dati.
Sono particolarmente interessanti le due formulazioni che vengono proposte per le
equazioni di aggiornamento e previsione del filtro di Kalman, da applicarsi nei casi in
cui:
Il punto 2 è molto interessante ai fini pratici dal momento che la maggior velocità di
acquisizione da parte dei sensori accelerometri rispetto ai sistemi satellitari è realtà
tecnologica.
In conclusione è stato proposto un sistema che preprocessa gli aspetti non lineari delle
acquisizioni GPS e accelerometriche prima di integrarle in un filtro di Kalman; il
preprocessing consente di ridurre considerevolmente le dimensioni delle matrici in gioco e
quindi ottenere una buona efficienza computazionale, anche se una precisione leggermente
ridotta rispetto all’utilizzo diretto di un filtro di Kalman che gestisca sia le non-linearità che
l’integrazione contemporaneamente.
In [9] viene proposto un sistema per il posizionamento di persone attraverso un sistema combinato con GPS e accelerometri. Le accelerazioni vengono misurate posizionando il sensore sul torace o sulla schiena: in questo contesto l’accelerometro non viene usato per misurare direttamente la lunghezza del passo, ma i dati accelerometrici vengono usati per stimare il tempo di volo del piede e misurare la frequenza dei passi; in base a questi due parametri viene proposto un modello per stimare la lunghezza della camminata all’interno di un filtro di Kalman che si occupa di integrare questi dati con i posizionamenti dal GPS. La strategia per il posizionamento proposta consiste nei seguenti passi:
In conclusione questo sistema è in grado di migliorare le misure satellitari, ovvero fornire misure
parziali tra un posizionamento GPS e l’altro e correggere parzialmente eventuali vuoti radio
temporanei, fino ad ottenere un errore sulla distanza percorsa finale nell’ordine del
2%.
In [15] viene presentata una valutazione dell’utilizzo di ricevitori GPS differenziali per la
misurazione di una camminata. I risultati mostrati sono molto incoraggianti: nonostante la
frequenza di campionamento relativamente bassa la posizione del piede viene individuata
con precisione.
Questo suggerisce la possibilità concreta di apportare correzioni efficaci al metodo
proposto nel capitolo 2 imponendo, con lo stesso metodo di correzione utilizzato
per correggere la misura dell’alzata, la posizione giusta sull’asse in direzione del
moto.
Per l’implementazione è stata scelta una struttura modulare che permette di utilizzare metodi di calcolo diversi riutilizzando tutto il codice che si occupa di disegnare i grafici e di acquisire o salvare i dati scambiati con l’accelerometro. In particolare sono state definite tre classi:
La prima si occupa di dialogare con l’accelerometro via bluetooth, la seconda implementa un metodo matematico mentre l’ultima funge da interfaccia con l’utente, occupandosi di salvare o caricare i dati su/da file, di disegnare i grafici e di comunicare con le altre due.
L’acquisizione in tempo reale dei dati via bluetooth è delegata a un semplice modulo software implementato appositamente per questo scopo: la classe DataCollector. L’idea che sta alla base di questa classe è molto semplice; un DataCollector è un oggetto che:
Di seguito una breve descrizione dell’interfaccia fornita:
Il calcolo effettivo della posizione dell’accelerometro nelle tre dimensioni è delegata a una
qualsiasi istanza della classe Method. Questa classe svolge una funzione di calcolo
“semi-realtime”, nel senso che ha sempre in memoria tutti i dati che gli sono stati passati
con il metodo compute, ma è libera di calcolare i dati relativi all’accelerazione e allo spazio
indietro nel tempo a discrezione del metodo matematico utilizzato, a condizione che la
lunghezza degli array dei dati sia sempre consistente.
Di seguito una breve descrizione dell’interfaccia fornita:
Questa classe è nata come “collante” tra il metodo matematico, l’interfaccia seriale e
l’utente: mentre queste ultime due difficilmente saranno soggette a cambiamenti, Locator è
pensata per essere plasmata in base allo scopo ultimo dell’applicazione. In questa
implementazione ci si limita a offrire la possibilità di salvare e leggere da file i dati
accelerometrici grezzi, e di disegnare su grafico o in 3D tramite OpenGL il risultato
dell’elaborazione del metodo.
È stata implementata anche DoubleLocator, che si avvale di due DataCollector e due
Method per acquisire e processare i dati di due accelerometri contemporaneamente al fine
di studiare una camminata completa.
Le principali caratteristiche hardware dell’accelerometro sono riassunte in tabella B.1. La
frequenza di campionamento dipende in primo luogo dalla velocità di trasmissione del
sistema bluetooth e quindi dalla risoluzione: le sperimentazioni sono state eseguite con una
frequenza di campionamento di circa 1Khz su tre assi ad 8bit. L’hardware permetterebbe di
salire in risoluzione, ma per esempio già a 10bit la trasmissione wireless non è abbastanza
veloce da permettere l’acquisizione ad 1Khz su tutti e tre gli assi, ovvero è necessario
abbassare la frequenza di campionamento oppure diminuire il numero di assi
considerati.
| Parameter | Test Condition | Min | Typ | Max |
| Acceleration Range | ±5.4 | ±6.0 | ||
| Sensitivity | Full Scale = 6g | Vdd/15 − 10 | Vdd/15 | Vdd/5 + 10 |
| Sensitivity change vs temp. | Delta from +25°C | ±0.01 | ||
| Zero-g lev. change vs temp. | Delta from +25°C | ±0.8 | ||
| Operating temp. range | −40 | +85 | ||

Sono stati eseguiti dei test per valutare la reale velocità di acquisizione (tabella B.2). L’accelerometro esegue circa 947 campionamenti al secondo; le fluttuazioni della tabella sono dovute alla temporizzazione non perfetta, conseguenza diretta dell’implementazione multithreading, che ha un effetto rilevante sui campionamenti di durata breve.
| Tempo di campionamento | Numero misure | Byte ricevuti | Campioni per asse / sec |
| 1sec | 32 | 3761.97 | 940.492 |
| 10sec | 15 | 37817.8 | 945.445 |
| 100sec | 32 | 378722.0 | 946.805 |
Misurando l’accelerazione di gravità si sono ottenuti dei valori leggermente diversi da quelli che ci si sarebbe aspettati dalle specifiche. In particolare l’apparecchio ha una risoluzione minore ed i fondi scala inferiore e superiore non corrispondono a 0 e a 255 rispettivamente ma sono ristretti all’interno di questo range, come si vede in tabella B.3.
| 0g | 1g | −1g | 2g in digits | +6g | −6g | risoluzione | |
| Asse X | 139 | 156 | 120 | 36 | 139+18*6=247 | 139-18*6=31 | 0.0597 |
| Asse Y | 143 | 160 | 126 | 34 | 143+17*6=245 | 143-17*6=41 | 0.0555 |
| Asse Z | 140 | 157 | 121 | 36 | 140+18*6=248 | 140-18*6=32 | 0.0555 |
[1] G. Welch; G. Bishop. An Introduction to the Kalman Filter. SIGGRAPH 2001, Course 8, University of North Carolina at Chapel Hill Department of Computer Science Chapel Hill, NC 27599-3175, 2001.
[2] T. Ford; J. Hamilton; M. Bobye; L. Day. GPS/MEMS Inertial Integration Methodology and Results.
[3] E. Fabri. Per un insegnamento moderno della relatività. Tipografia Editrice Pisana, Pisa, 1989.
[4] G. T. French. Understanding the GPS. GeoResearch, Inc., 8120 Woodmont Avenue, Suite 300 Bethesda, MD 20814, 1996.
[5] G. Pang; H.Liu. Evaluation of a Low-cost MEMS Accelerometer for Distance Measurement. Journal of Intelligent and Robotic Systems 30: 249-265, Netherlands, 2001.
[6] Y. K. Thong; M. S. Woolfson; J. A. Crowe; B. R. Hayes-Gill; D. A. Jones. Numerical double integration of acceleration measurements in noise. www.sciencedirect.com, ELSEVIER, 2004.
[7] Y. K. Thong; M. S. Woolfson; J. A. Crowe; B. R. Hayes-Gill; D. A. Jones and R. E. Challis. Dependence of inertial measurements of distance on accelerometer noise. Meas.Sci.Technol. 13 (2002) 1163-1172, 2002.
[8] R. E. Kalman. A New Approach to Linear Filtering and Prediction Problems. Transactions of the ASME-Journal of Basic Engineering, 82 (Series D): 35-45. Copyright ©1960 by ASME, 1960.
[9] Q. Ladetto. On foot navigation : continuous step calibration using both complementary recursive prediction and adaptive Kalman filtering. Geodetic Laboratory, Institute of Geomatics, Swiss Federal Institute of Technology.
[10] M. H. Goldwasser; D. Letscher. Object Oriented Programming in Python. Paperback.
[11] Honghui Qi; John B. Moore. A Direct Kalman Filtering Approach for GPS/INS Integration.
[12] T. E. Oliphant. Guide to NumPy. 2006.
[13] H.Liu; G. Pang. Accelerometer for Mobile Robot Positioning. The University of Hong Kong, 1999.
[14] A. D. Cheok; K. G. Kumar; S. Prince. Micro-Accelerometer based Hardware Interfaces for Wearable Computer Mixed Reality Applications. Proceedings of the 6th International Symposium on Wearable Computers (ISWC’02), 2002.
[15] P. Terrier; Q. Ladetto; Bertrand Merminod; Y. Schutz. High-precision satellite positioning system as a new tool to study the biomechanics of human locomotion. Journal of Biomechanics 33 (2000) 1717-1722, 2000.
[16] D. Simon. Kalman Filtering. Embedded System Programming, June 2001, 2001.
[17] J. Bao; Y. Tsui. Fundamentals of Global Positioning System Receivers. John Wiley & Sons, Inc., 2005.
[18] R. M. Wald. General Relativity. The University of Chicago Press, London, 1984.
[19] D. Halliday; R. Resnick; J. Walker. Fundamentals of Physics. John Wiley & Sons, Inc., 2005.
[20] M. Welling. The Kalman Filter. California Institute of Technology.